
How we watermark things
A quick explanation of how we add metadata to content.

Today, many people can spot things that were created by an AI. The photo might have weird ears and hands; the music might sound strangely distorted; the wording might seem bland. But AI is getting dramatically better, staggeringly quickly. When AI-generated content is indistinguishable from human content, how will we tell the two apart?
There are a few reasons we might want to do so:
To fight disinformation. Knowing that an adversarial bot is in your Facebook feed fomenting dissent and stirring up controversy could change how you react to it. We’ve already seen the effects of this behaviour on elections around the world.
To block spam. Generative AI makes it much, much cheaper to automate content generation, stuffing our inboxes with unwanted nonsense.
To stop AI from training itself on AI, and making future versions of itself less effective in the process. Tracy Durnell has written eloquently about the challenges of an AI that consumes AI-generated content. As millions of users take the content that chatbots hallucinate, and share it online, it becomes harder to distinguish what’s truth from what’s made up.
How do we mark digital content?
One of the fundamental things about the digital realm is that a copy is indistinguishable from the original. If you have two files that are identical, there’s no way to tell which one is a copy of the other. So we have to add something to the content to mark it somehow, creating a sort of uniqueness or permanence. At its core, that’s what crypto is about: Making impermanent digital things behave like permanent physical things.
The honor system
We could just trust everyone to tell the truth, and mark their AI-generated content as coming from a machine. I’m only mentioning this to point out how ridiculous the notion is; clearly, people would forget to do so, and bad actors would lie. Some platforms are trying to mark bot accounts as different from human ones, but this isn’t going to solve our problem.
File system metadata
Metadata is simply “data about the thing that isn’t the thing.” Every digital object has properties that describe it, such as the number of bytes it takes up, or when it was created, or what kind of file it is, or who made it.
The easiest way to “mark” something is to change how it’s stored. You can manually edit a filename, and then search for that filename later and find it. This is like changing the label on a filing cabinet—you’re not changing the document, just adding context.
Modern computer file systems add a ton of metadata about the things they store. For example, I have an image on my computer that’s part of the digital content for Underworld’s 2010 track Barking. When I hit command-I on my Mac, I see a ton of information about what kind of file it is, how big it is, and where it came from. If I’d downloaded this picture from the Internet, that would be listed too.

But this isn’t really trustworthy information about the contents. I could edit it manually if I wanted. It’s separate from the file itself. If I send the image to someone else, the details about where it lives on my hard drive are not included.
Metadata within the file itself
What about data that’s part of the file itself? Some media types have metadata within the files themselves. If I try to open a photo with my computer’s text editor, I can’t really make sense of what’s there—but I can see that it was created in Photoshop 3.0. This stuff is in the content itself.

Images, for example, have Exchangeable Image File Format (Exif) data in them. Since 1998, camera manufacturers got together and agreed that, in addition to the pixels of the photo, they’d encode things like the date and time the picture was taken, the kind of compression used to make the file smaller, whether a flash fired, and other useful facts about the images.
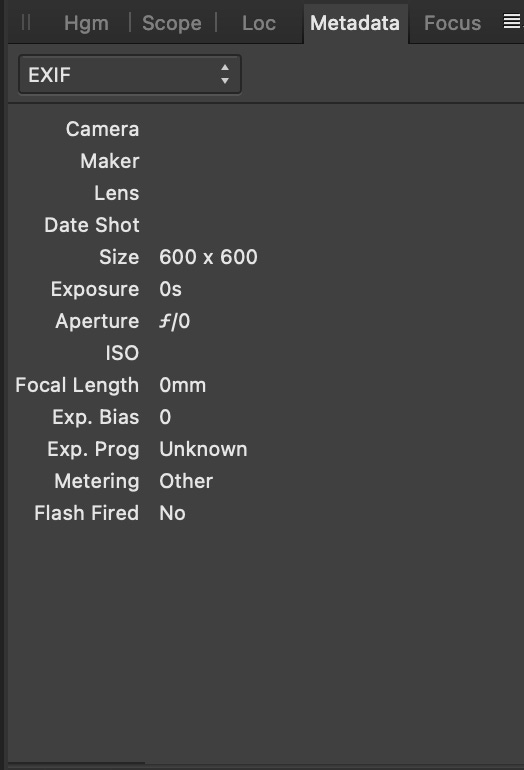
Unlike file system information, Exif data is part of the file itself, meaning that if I send it to someone else, it’s still there. But there are tools to remove Exif data (which is a good idea if you value your privacy. You can open an image, delete the metadata, and save it with a new name. So we can’t really trust that either.
Steganography
There’s a way to hide information within the pixels themselves called steganography. This alters the content of the image in ways a machine can notice, but a human won’t. It was initially used to transmit secret messages within seemingly innocuous content, but today it’s used for all sorts of things. Here’s a very simplified example:
Computers represent color as the amount of red, green, and blue in each pixel, on a scale from 0 to 255. Here’s a row of red squares, all the same color: 237/255 red, 34/255 green, and 13/255 blue:

I can alter the amount of red, green, and blue in each square by a small amount without someone noticing:

These squares are all side by side; it’s much harder to notice subtle differences when they’re in a photograph where every pixel is already slightly different from those around it. Steganography exploits this fact to hide a message inside the content itself. This is much harder to remove, because it’s harder to extract (for one thing, it helps to know what the original image is like, so you can calculate the differences.) Steganography is how we watermark images today.
Because I’m a stickler for details, I put these in a single image that shows the raw data, with all these kinds of “proof of provenance”:

The problem with text
But none of these will mark text. And that’s a big problem, because text is the bulk of our online communication. From websites to emails to blog posts to chatrooms, text is the bare metal of the online world. It’s the fundamental, basic thing, whether you’re using an old dial-up modem on a BBS or the latest web browser to send prompts to a rack of GPUs halfway around the world.
Let’s nerd out about text a bit.
ASCII and Unicode
The American Standard Code for Information Interchange, or ASCII, is simply a numbered list of letters. The numbers go from 0 to 255 (a byte, or 8 bits.) 32 is a space; 65 is an uppercase A. Once upon a time I knew them off by heart. My Apple ][+ only used the numbers from 0 to 127 for some pretty nerdy reasons.*
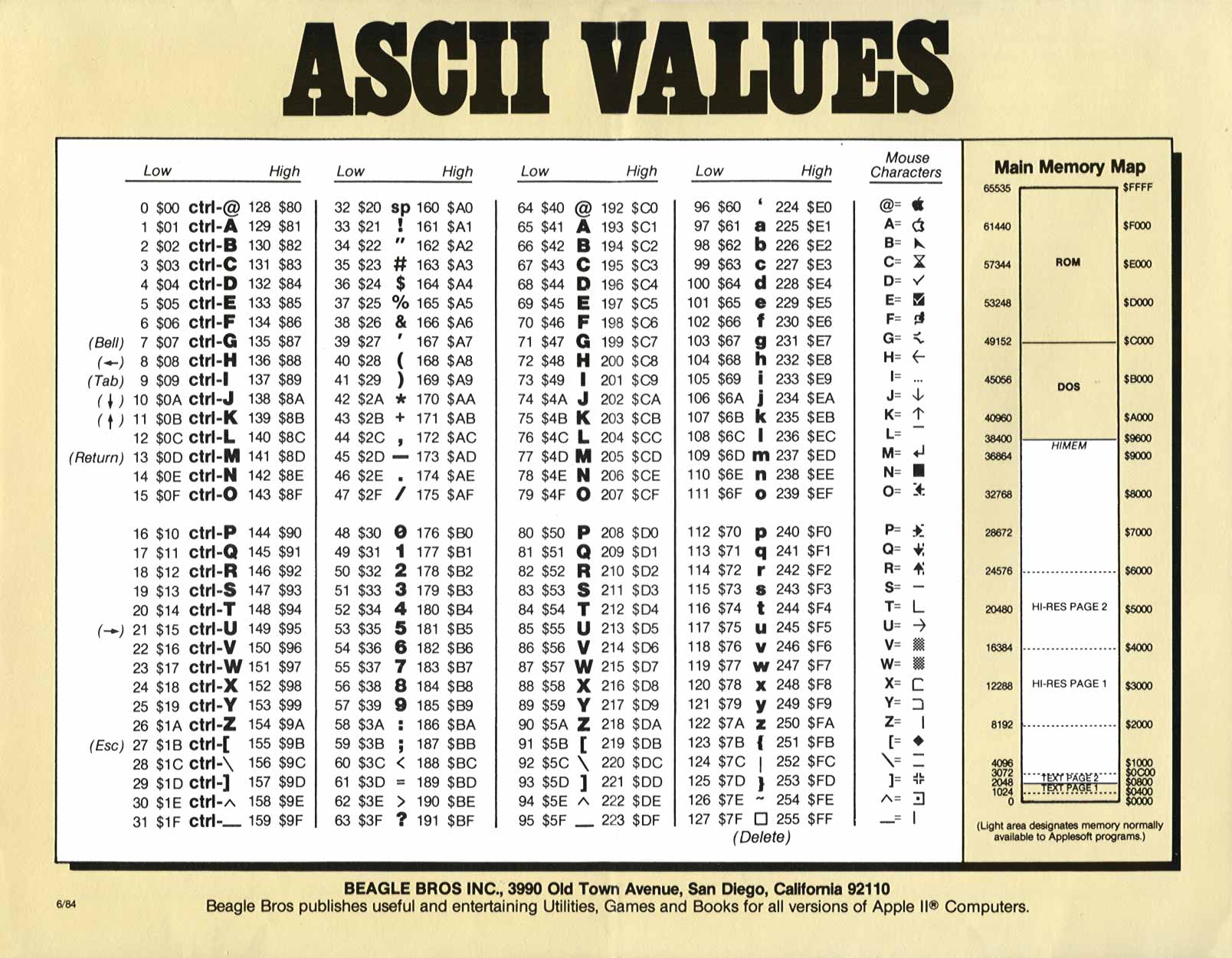
This was pure, unvarnished content. If you got a series of electrical pulses that went on-off-off-off-off-off-on, or 1000001, you had an A. That’s as low as it goes; any lower and you’re into flashes of light, or sounds on a modem.
Soon, though, computer manufacturers broke the standarde. The IBM PC had a character set that included corners, lines, cursors, and other shapes useful for designing text-based user interfaces.

This inconsistency made it hard for different computers and different brands of software to communicate. Something that looked correct on one machine might be nonsense on another. Different countries needed different character sets to support their unique accents and letters. At the same time, computers were getting more powerful, and communications was speeding up. What if we used two bytes instead of one to represent characters? We’d 16 bits instead of 8, which meant 65,536 possible characters instead of just 256, more than enough to represent all the letters from all the languages.
So in 1988, Joe Becker proposed a new standard, called Unicode, which referred to the new list of characters as “wide-body ASCII.” By 1996, Unicode 2.0 allowed values bigger than 16 bits, so we could store things like hieroglyphs and rarely-used Chinese or Japanese characters.
I think it’s time to give Unicode a makeover, which I’ve written about in a separate post, Unicode is all you need.
Postscript
In the early days of telecommunications, links weren’t very reliable. Sometimes, in addition to a character, the sender transmitted a parity bit: 0 if the other numbers were even, 1 if they were odd. This gave the computers at either end a chance of detecting a mistake due to interference on the line. See https://en.wikipedia.org/wiki/8-N-1 if you care about such things.