
Unicode is all you need
A simple idea for marking AI-generated content would have wide-ranging benefits for humans.

This post goes into more detail—with some concrete examples and additional thoughts—about the idea behind the recent Wired Op/ed I wrote on the subject of granular, persistent AI watermarking.
TL;DR: Mark AI-written text with different Unicode values so that we can distinguish AI-written text from human-written text even though the letters look the same. Unicode works across all devices and websites, and doesn’t need any changes to how people use the Internet. Plus, the people behind the Unicode governing body include many of the companies who are building Generative AI.
A world where we can tell the difference between human- and machine-generated content is better for humanity. We have labels for the things we put in our bodies; we should care as much about what we put in our minds.
Last week, many of the tech giants behind Generative AI agreed to watermark the content their AIs create. That’s a laudable goal, but one that’s noticeably short on details.
What do they mean by watermark, anyway?
As early as the 1200s, papermakers used to create distinctive patterns on paper by varying the thickness of the paper while it was still wet. More recently, the term “watermark” has been used to describe any embedded symbol that uniquely identifies something, from custom markings on money to heraldry on stationery to patterns on stamps.
In the digital world, a “watermark” is a unique identifier attached to some content, often used to prevent illegal copying or prove its origin. Digital watermarks are hard to implement. There are three basic ways to mark something online:
Steganography is the practice of hiding one message within another. Originally used by spies to smuggle information out, today we use it to embed a digital marking in an image or audio file. Tiny variances, imperceptible to a human, can be extracted from the content to prove its origin.
Metadata means adding extra information to something.
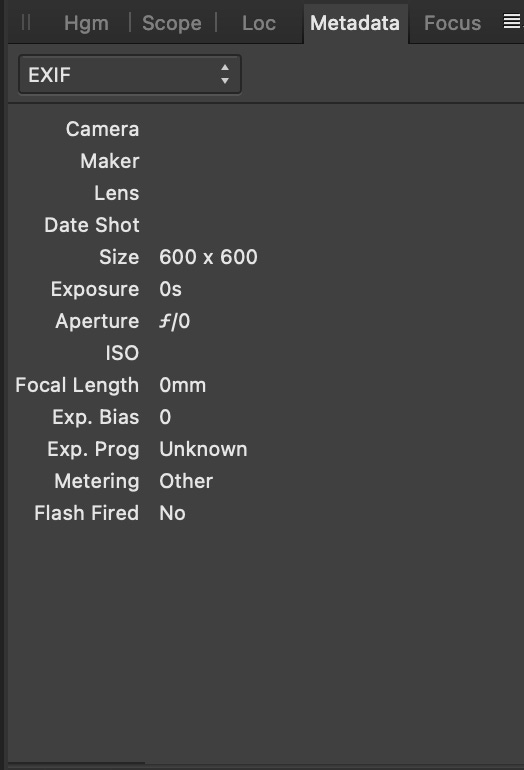
Digital cameras add EXIF (Exchangeable image file format) data to photographs. This metadata includes things like the date and time the picture was taken, the kind of compression used to make the file smaller, whether a flash fired, and other useful facts about the images:

An image that wasn’t taken by a camera may not have Exif metadata—or it may just have been deleted. Unlike file system information, Exif data is part of the file itself, meaning that if I send it to someone else, it’s still there. But there are tools to remove Exif data (which is a good idea if you value your privacy. You can open an image, delete the metadata, and save it with a new name. So we can’t really trust that either.
Modern computer file systems add a ton of metadata about the things they store. For example, I have an image on my computer that’s part of the digital content for Underworld’s 2010 track Barking. When I hit command-I on my Mac, I see a ton of information about what kind of file it is, how big it is, and where it came from. If I’d downloaded this picture from the Internet, that would be listed too.

The information my file system has stored about an image for a song. But this isn’t really trustworthy information about the contents. I could edit it manually if I wanted. It’s separate from the file itself. If I send the image to someone else, the details about where it lives on my hard drive are not included.
Word processors mark things up as well. When some text is bold, it’s surrounded by hidden information that identifies the change in the text. Web pages use Cascading Style Sheets and HTML to mark up text so that browsers can format it and display it correctly.
Encryption. Digital signing works by taking a block of content, such as a chapter of text, and doing something computationally intensive to it to generate a unique string of numbers (this is known as hashing.) If the content is altered, then the string changes.

All three are complex and cumbersome.
Steganography requires a copy of the original message, and only works with big objects like an image, a song, or a video.
Metadata is application specific. If you copy some bold text into your browser’s address bar, then paste it back into a word processor, the formatting is lost.
Digital signing requires a trusted central authority or a distributed ledger, which is why that movie you bought on iTunes only plays on your Apple device, or why your NFT exists even when you’re not online.
What’s more, the future is human/machine collaboration. It’s likely you’ll have a block of text that was generated by an LLM, then edited by a human, until it’s blended on a word-by-word or letter-by-letter basis. Watermarking makes something like a block of text rigid and unchangeable; it doesn’t really work in a world where content is the result of humans and AIs working side by side.
What we really need is a way to mark individual characters—text itself—as generated by a human or an AI. This marking should be inseparable from the content it marks, and should persist whether text is copied, pasted, shared across apps, transmitted to other operating systems, or sent to other devices.
I think there’s a way to do it, without rebuilding the Internet from scratch.

Give AI its own character set
My first job out of college was product manager for foreign language versions of a DOS SNA client at a company called Eicon Technology. I learned a lot about how computers handle foreign languages that year, and it was complicated. Most machines stored letters in eight bits—256 possible values—which meant that when you needed to change languages, you changed character sets. Something written in Turkish, for example, looked like nonsense when you read it in English.
A few years later, a standard called Unicode came out that could handle hundreds of thousands of letters. It used up to four bytes (something called Unicode Transformation Format-8, or UTF-8) to store 1,112,064 possible characters. Unicode is the thing that lets all humans use the Internet together. It’s also the thing that certifies new emojis. The Internet is literally built on Unicode text; in fact, nearly 98% of websites support it.
And it turns out, Unicode can be a really good way to watermark AI text.
A concrete example
Unicode has many different versions of the letter A. Some are for accents, some are for mathematical formulae, and some are just wide or heavier.

How would this work? Since we don’t have a Unicode character named “LATIN CAPITAL LETTER A MADE BY AN AI”, let’s instead use the existing “MATHEMATICAL SANS-SERIF CAPITAL” characters that do exist in Unicode already. We can do this right here in this post—after all, it contains Unicode, which the web already supports.
The word ‘TEST’ and the word ‘𝖳𝖤𝖲𝖳’ in this sentence appear similar, but are actually using entirely different Unicode values. The first TEST uses the regular letters you read all the time; the second 𝖳𝖤𝖲𝖳 uses a second set of characters used for mathematical equations. That’s why the fonts look different (this is also how people get those weird letters in their Twitter profiles.)
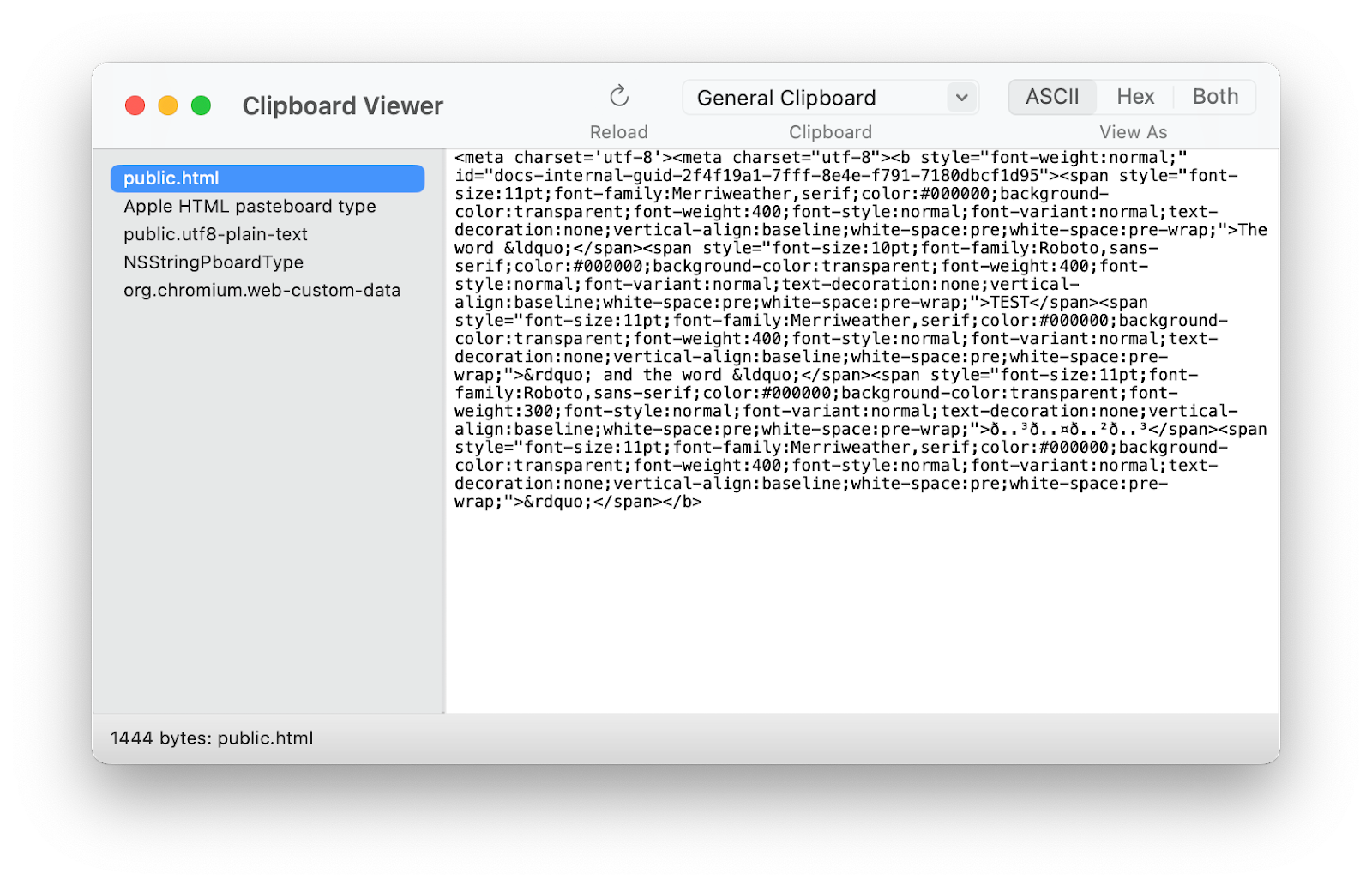
You can try copying and pasting them from this document into another app or device—they’ll stay the same, because they’re actually different letters. If you paste the second “𝖳𝖤𝖲𝖳” into Apple’s developer tools Clipboard Viewer utility, you’ll see the difference:

As the clipboard viewer shows, there are many different encodings of the text in your clipboard: Rich Text format, HTML, and even legacy formats like the NeXT Rich Text Format are all listed on the left. But the “root level” encoding is UTF-8. Every character has a number, and these bytecodes are those numbers.
If I select “The word ‘TEST’ and the word ‘𝖳𝖤𝖲𝖳’” from this document, I can see metadata in the clipboard adding information such as the font, line spacing, and alignment:
Let’s try pasting that text into something that ignores formatting (such as the address bar of a browser.)

And then copying it, and viewing the contents of the clipboard again:

While the metadata and formatting information has been stripped as result of pasting it into a browser address bar (which does not support rich text formatting) and copying it, the encoding of the alternate characters for 𝖳𝖤𝖲𝖳 remain. That’s because Unicode is an encoding in which the content (the character) and the context (AI or human) are inseparable.
AI- and human-written letters can be identical (so all characters look the same, i.e. have the same glyphs) but the underlying values will be different, allowing anyone to view them easily with a “show AI” button.
Some other thoughts
I’ve submitted a more detailed version of this as an ArXiV paper, which will hopefully be approved for publication. There are plenty of details to consider, some of which I’ve listed below. I’m sure I’ve missed a ton of them. But the approach has serious merits if we want to watermark AI while still working alongside it.
This is a highlighter, not an enforcement system
I’m proposing a highlighter, not how to use it or what to do when someone doesn’t. The highlight wouldn’t be visible unless activated (AI letter ‘A’ and human letter ‘A’ would use the same glyph and look identical.)
Nothing about this idea enforces AI text marking. It’s simply a mechanism for marking things. We can let marketers, governments, and the legal system decide who should be marking AI content, when it’s okay to remove the markings, and what to do if someone removes them inappropriately.
What’s more, if you don’t trust the source, you can always use digital signing as well. Get the blended text using Unicode, then sign the whole thing. It won’t be editable without breaking the signature, but the markup will persist either way.
It’s still a lot of work
There’s also a lot of work to make this happen. Files might get bigger; font glyphs will have to change; search engines will need to process an AI letter in the same way they process a human letter; text-to-speech systems need to be updated so we don’t marginalize some people or widen the digital divide. I’m sure I haven’t considered a ton of challenges. But Unicode is already supported across every major operating system, application, and device. It’s just sitting there, waiting to solve this watermarking problem. We created Unicode so that all humans could use the Internet; now we can use it to identify the things humans have created.
It’s easy for someone to cheat
It’s trivially easy for a bad actor to remove AI markup from text. That’s not the point. Bad people lie all the time; if Large Language Models like ChatGPT, Claude, Bing and Bard mark the content they generate in this way, then if it disappears, someone knowingly removed it. If that harms somebody, we have a legal system to deal with it.
Similarly, it’s easy for a good actor to pledge to be AI transparent. They can preserve the markings, letting their customers know what was made by a human and what was written by an AI. We should normalize this: Let brands decide their stance on AI-generated support chat, or marketing copy, or social bots, and have users decide what they want.
There are plenty of use cases
A “track changes for AI” approach has hundreds of use cases, from teachers who can see which parts of their students’ work was generated by an AI to workers giving feedback to their colleagues’ work, to regulated businesses enforcing chain-of-custody on generative content. With Unicode, all of these are instantly possible—with a software update.
The Unicode Consortium members are Big Tech
Better still, many of the companies on the Unicode steering committee are the same companies that are building generative AI: Microsoft, Google, Facebook, IBM, and others. It’s in their best interest to use this ready-made tool to help us navigate an Internet where both humans and algorithms are generating content.
Conclusions
In a perfect world, we’d have seen Generative AI coming, and set up our communication systems at the dawn of the Internet so that things created by a human were provably, demonstrably, different from things created by a machine. That would be a very different world from the one in which we live today. I think it would be a much better one.
The encoding system within Unicode presents a unique opportunity to do so with comparatively little effort. It is widely deployed and tested; works across many languages, organizations, and applications; has an existing governing and regulatory body; involves the major technology vendors; and can be adopted voluntarily.
We have labels for the things we put in our bodies—gluten-free, organic, non-GMO, vegetarian. We should care as much about what we put in our minds.
Stumbled across your article when researching this exact thing. Love your idea (was going down the same thought process too) of using unicode characters to indicate ai, I did find this one: 𐓙 (U+104D9) that is literally 'Ai'