


The Affirmative Action of Vocabulary
AI is prejudice at scale. How should we react?

Most machine learning is literally prejudice—telling a machine, “based on what you’ve seen in the past, predict the future.” But what do we do when it’s also correct?
Many of the most popular examples of “artificial intelligence” today are actually about classification. For example, we can show a computer past pictures of dogs, and have it predict whether a new picture is a dog (or a pastry.)

Modern humans use their computers to distinguish dogs from muffins, bagels, and croissants. Good job, humanity.
We can also use those predictions to do things like mimic an art style, or try and anticipate what word will come next in a sentence, or suggest people with whom you might want to connect. Most of these seem pretty whimsical; but often, that prediction has very real human consequences.
Word analogies
A frequent target of such criticism is Word2vec, a body of 3M words taken from the last 50 years of journalism. It’s used to train algorithms for things like sentiment analysis, predictive typing, automatic proofreading, and so on. Researchers have examined the relationship between words, and as you might expect, some words go together more often than others. You can ask the data to associate terms and it will show that “Man is to King as Woman is to Queen.”
Which seems fair.
You can also ask it to make predictions. If you ask, “Paris is to France as Tokyo is to …” the data will correctly predict “Japan.”
So far, so good.
But you can also ask it to associate words with a particular vector in mind. You can say “He is to pilot as she is to …” And that’s where the problems begin. It thinks that the female version of a computer programmer is a homemaker. And the female version of a doctor is a nurse.
And that’s sexist.
On the other hand, many associations are gender-related, but not sexist. The female version of a monastery is a convent; the female version of a briefcase is a handbag; and so on.
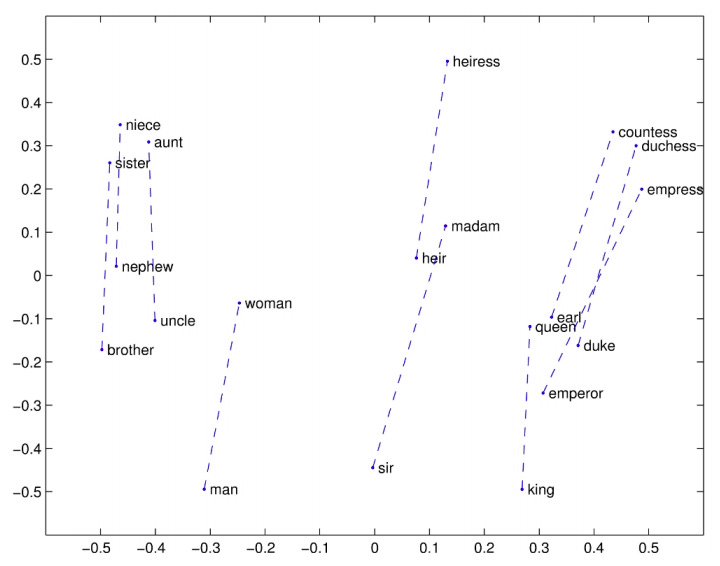
Global vectors for word representation showing some examples of word associations along a gender vector.
That’s actually helpful. If you’re looking for the female version of “heir,” this tells you what word to use.
Often true, seldom aspirational
Often, the algorithms’ predictions are factually correct. In an analysis of 150 years of British periodicals, researchers were able to accurately detect changes in society: When electricity replaced steam; when trains replaced horses; epidemics; wars; and so on. But the key here is history: The data on which the algorithms were trained comes from the past. The British periodicals study was also able to detect the under-representation of women in the media.
That’s a mixed bag of usefulness.
In a research paper entitled “Semantics derived automatically from language
corpora necessarily contain human biases,” the authors look deeper into this issue, tackling things like racial bias, gender bias, and more. One of their findings is fascinating: The data describes the real world. If the algorithm thinks that a job is strongly associated with a gender, the strength of that association is a good predictor of gender makeup of that job.
In other words, the algorithm is a jerk for thinking that women are nurses and men are doctors. But it’s also probably correct. Given no other information than “this person is a nurse,” you would be wise to assume that the person is a woman, on a purely probabilistic (but obviously prejudiced) level.
Here’s a chart of 50 jobs analyzed in the study, showing how strongly that job is associated with the female gender, and what the actual gender representation is:
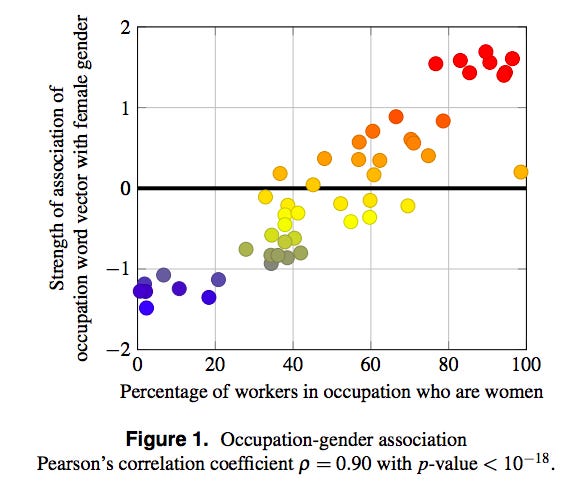
It makes technically good predictions that are morally bad.
In the United States, 83% of nurses are female. The gender mix has changed significantly in recent years: 96.1% of nurses were female in 1970, and 91.9% were female in 2011. But at the same time, this gender bias is actually an accurate representation of the data; analyzing it over time, we could even predict a trendline of changes.
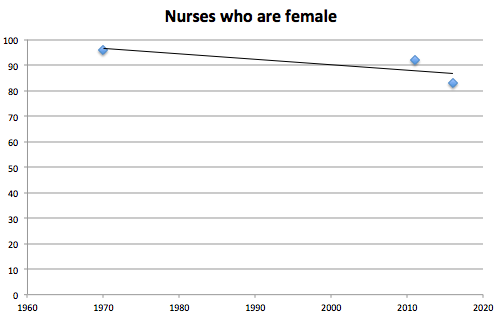
A very badly done trendline to make my point.
Don’t change the future by reinforcing the past
Data ethics is complicated stuff. The issue here is that historical data used for training purposes—like Word2vec, or 150 years of British periodicals, or the entire body of Enron emails—aren’t wrong. They’re actually frighteningly right. Rather, the issue is that we shouldn’t incorporate these assumptions in ways that change the future by reinforcing the past.
Here’s an example.
If I type “my friend is a nurse, and” into my Google Pixel, I get suggestions for the next word. You can probably guess what they look like.

Are these suggestions helpful?
As expected, two of the three suggestions are “she.” And it turns out there is an 83% chance that is accurate. But do we want to subconsciously reinforce for every smartphone user that they should expect women to be nurses? Should we suggest “she” 83% of the time and “he” 17%? Should we change the ratios to 50% as a form of vocabulary affirmative action?
Data ethics is complicated. Algorithms are prejudice. As we let computers and data shape more and more about the world around us, we need to decide how we use that data. Just because it’s correct in the past doesn’t make it right for the future.