
Do you want to play a game?
What a summer learning to code taught me about politics and law

Hey there! Before we get started down a rabbithole of old computers and the legal system: Finally, on Friday, June 12, I’ll be talking with behavioural economist Supriya Syal about how people form communities and meet others, which seems particularly relevant given our socially distant lifestyles.
Do you want to play a game?
My first computer was a Golden ][, a thinly-veiled knockoff of an Apple ][ with manuals that had been mangled from English to Chinese and back, making them almost unintelligible. My dad had died the year before; my mom had bought the second-hand clone from a well-to-do classmate of mine whose father had finally concluded that he wanted the real thing instead of this fake.
I took to it like a toddler to a Christmas tree: Unhesitating, absolutely certain there were treasures hidden inside, and mindless of what I might shatter on my way to unearth them.
I was twelve.
My initial, naive plan was to write an Apple version of Robotron, which I’d just seen in an Arcade. I didn’t get very far—Apple BASIC wasn’t known for its speed. But it did force me to crack open the manual a little wider, and read a bit more. I started poring over others’ code, trying to make sense of it. Over the next couple of years, as I built and ran a BBS for my friends, I figured out certain patterns that I’d use over and over.
Today, computer scientists have names for these patterns: Functions, data structures, subroutines and frameworks. Components you re-use all the time, from sorting a list to recovering a password.
Linked Lists
On the Apple ][, these were fairly primitive building blocks. For example, programmers often have to add, or delete, things from a list. A linked list is a list of things that are linked in a sequence. The word processor on which I’m writing this is a linked list of characters; when I delete a character, the one before it is now linked to the one after it.
Imagine I have fruits instead of characters, and I’m sorting them alphabetically. The simplest way to do this is to place them in order—whether they’re fruits on a table, or a list of fruit names in computer memory:

Now imagine I want to add a cantaloupe to my list (or table.) This takes a couple of steps: First, I move the cranberry over roughly the width of the cantaloupe; and second, I put the cantaloupe in its place:

But what if that cantaloupe is so huge, it’s hard to lift? And what if I have other fruits after the cranberry? Then, every new fruit I add means moving all the fruit that come after it:

Zucchini is a fruit. Don’t @ me.
It gets even more complicated when we consider sorting them in some other way—for example by size or by color—and have to carry all those fruits around (by hand, or in the computer’s memory.)
There’s a different way to do this, by having each fruit “point” to the one after it. In this example, the Apple says “the Blackberry comes after me,” and the Blackberry says “the Cranberry comes after me”:

To insert Cantaloupe, I first change Blackberry to say, “the Cantaloupe comes after me,” and then make Cantaloupe say, “the Cranberry comes after me.” Most importantly, I don’t have to move the fruit, just the pointers:

This means only two actions regardless of how long the list is:

Data structures like linked lists mattered, back then, because memory was really, really scarce, and moving things around in it was no fun at all. If those things were big, then it was much easier to just “point at” them. Also, you can have one thing point to several, or vice-versa, depending on something else.
What I learned from ANIMALS
Anyway, the way I learned all this was by playing, and reading the code for, a game called ANIMALS. ANIMALS was an Integer BASIC demonstration of a linked list that showed you how to use the disk to store the big things, and the (precious) memory to store the pointers. This thing shipped with pretty much every Apple. It started as a simple guessing game.
“Oh, hey, I bet the code is on the web somewhere,” I think smugly. How naive I am. The whole machine, with all of the utility disks I coveted as a teenager, is on the web. For free. In Javascript.

Twelve year old me is freaking out right now.
So I dusted off a bit of my mad DOS skills, and decided to run ANIMALS for you.
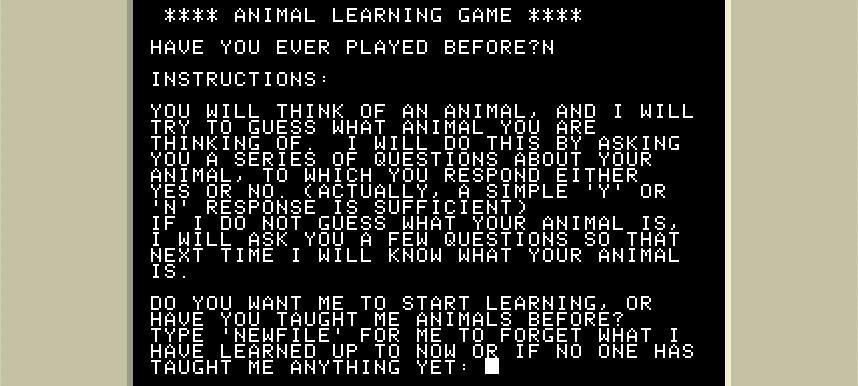
It’s a simple guessing game. It begins, the first time you play, knowing only two animals: A moose and a frog. It knows that the frog lives in the water, but the moose does not.

When it guesses wrongly, it asks for help differentiating its mistake from the correct answer, and then remembers it for future games. You may have seen a toy that always wins at 20 questions: This is how it wins.
When you start the game, its knowledge looks like this:

But once you teach it the difference between a tiger and a moose it looks like this:

The more people play it—assuming they give it correct answers—the smarter it gets. Over time, you’re training an expert system.
ANIMALS had a big flaw, however: If you used an unusually specific classifier early on, it became almost comically obsessed. The initial choice, “does the animal live in water,” is a good split (though only 20% of creatures do.) A decent next split might be “does it have a spine?” (but only 10% do.)
(If we did this over time, we’d get a tree that looks something like the following illustration, which is the only image in Darwin’s The Origin of Species.)

But imagine you’re thinking of a seahorse, and you’re a bit of a trivia buff. So when ANIMALS asks you, “what’s the difference between a frog and a seahorse?” you give it the question, “does the male carry eggs for up to 45 days in a pouch on the front of its tail?”

I mean, that’s technically right, but it’s oddly specific. It also means that to get to pretty much everything else in water you’re going to have to answer that damned egg pouch question. Resolution takes longer because of a too-narrow classifier close to the top of the decision tree.
Part of the work of Machine Learning and Artificial Intelligence is using math to move “good” questions— those that get to the right answer quickly by evenly splitting the tree—near the top of this branching list. Good taxonomies are clear and structured and easy to navigate, which means they need a lot of curation.
Anyway, ANIMALS was my first encounter with something that seemed able to learn, from one person or many, that I could take apart and try to understand.
The great battle in society
Here’s a workable definition of a society: A group of people who consent to be ruled by a set of laws, including the law that those who disobey those rules will be punished.
I firmly believe that the great battle in society, if not in nature itself, is the tension between individuality and collectivism. We see this play out in almost every social issue, from healthcare to taxation to racism to national security:
It makes us wear masks—or ridicule those who do.
It makes us vaccinate our kids—or spend our nights sharing medical fakery.
It makes us take to the streets, or hide in our bunkers.
It makes us clamour for handouts, or hide our fortunes offshore.
All creatures are wired with this individual-versus-collective urge. On the one hand, the organism wants to conserve resources and stay safe to pass its genes and ideas to the next generation; on the other hand, it needs to help the rest of its tribe so it receives food, protection, and reproduction.
Because everyone is constantly running a subconscious calculus of how to be as lazy as possible but no lazier, society is, too. Every citizen is running the math, because even altruism is the product of natural selection. Tax the rich, but only enough to keep the pitchforks from the streets. Let government intervene, but as little as necessary. And so on.
In most democracies, individuality and collectivism are enshrined in the vote and the constitution. The vote protects the many from the selfishness of the one, while the constitution protects the one from the tyranny of the many. A healthy, functioning society has agreed on a set of rules for the many and rights for the few, written them into law, and created a system to thoughtfully adjust them as needed.
There are plenty of unhealthy societies
In many countries around the world, there is no longer agreement. Citizens don’t know what their countries stand for. They feel the laws no longer align with the society to which they belong.
One reason for sense of disconnection between ourselves and the laws that govern us is the abundant, free communication of the modern world. If you were the village nerd, you had plenty in common with your fellow villagers, because you hadn’t met the other nerds yet (yes, that may be autobiographical.) Today, we’re much more likely to find our tribe online, and think of that as our society, and expect to be judged by its morals. We reject the physical state for the online village.
Another reason for this sense of estrangement is disagreement over what fairness means. “Give us a chance, and equal footing, for fairness is equality!” says one group. “Stay away from my stuff, I earned it, for fairness is equity!” replies another. We have two very different classes—that appear to live by different laws—and now that the wealth gap is a gaping chasm, we have two (or more!) societies within a physical location.
Is it any wonder the chaos around us?
Can an algorithm analyze how far we are from our laws?
Which got me thinking about ANIMALS.
Could we build a set of laws—and see how our preferences differed by race, ideology, geography, income, and more—by answering simple questions?
First, build a tree with simple choices
First, present a series of collective-versus-individual tradeoffs and tell the person how the current law would judge them. A simulation, of sorts. For example: Is a murderer guilty? An initial branch might look like this:

Then ask them if they agree with that treatment, and if they don’t, to provide a reason why. Learn where the edge cases and unfairness lie. One level deeper we might go:

This is much harder than telling a game that tigers have stripes, of course, but data science has changed a lot between the arrival of my Golden ][ and a world where I can run the whole Apple catalog in a tab of a browser for free. We have tools to parse sentences, tools to summarize text, tools to reveal linkages. Take this example of the 1897 German Civil Code, visualized as a series of arcs to show which parts link to which other parts:

Or this AI-based survey of over 1.5 million civil laws, in which the algorithm extracted the penalties from each law by “reading” it:

Some of this technology has a long way to go. I fed a post I wrote earlier called The Only Game Worth Playing into a free summarization tool; the results were nonsense. Nevertheless, there’s good reason to believe technology that can make sense of prose and legal text is nearly ready for the mainstream.
Our research would be made up of a series of A/B questions—simple to administer over a mobile device as a quiz or what-if. While the underlying technology would be complex, almost everyone of voting age could access the questions.
Second, prune the tree
The result of that analysis is a massive amount of data, like a collective game of ANIMALS, played by all citizens, but about the law.
But which factors matter most in the tree we’ve grown together? Which laws are good Occam’s Razors? For example, in law, intent is a significant factor in assigning wrongdoing. “Did the person intend to do this thing?” might be a good early question.
It is incredibly important, and difficult, to get this right. In the same way that a seahorse expert might push for egg-pouch questions early on, a special interest group will want their particular questions earlier in the process—because then the particular justice they seek will be served more swiftly, with less deliberation.
This is where the good of the many (the vote) and the rights of the individual (the constitution) get negotiated.

Today, we have machine learning algorithms that do exactly this: Find the classifiers that, in most cases, find the correct answer in the fewest possible classifications. We could apply them to the pruning of the branches, with great advantage:
To discern what particular moral tree a society agrees on.
To show us where there are gaps in the law.
To reveal obscure laws (like the U.S. Federal law that prohibits making a jam from more than five fruits) which might deserve to be struck from the books.
To see how legal opinions are shifting, and inform judges about public sentiment that could improve their rulings in a rapidly changing world.
Machine learning algorithms produce a model—a set of decision-making rules learned by analyzing data. But data scientists know that models drift over time, and don’t respond well to unexpected changes (for example, all business plans about the start of 2020 were wrong, because they didn’t factor in a global pandemic.)
Knowing how to stop models from drifting too far by updating and retraining them based on new data is a big part of successful AI. Similarly, knowing how to stop laws from becoming outdated or misinterpreted as society changes is a big part of successful government.
Third, segment and understand
But the real value here isn’t the generation of a legal system, it’s the disagreements. While a tree will emerge, its branches will vary by individual or group. And because we can segment that by demographic data—age, race, religion, sexual orientation, and more—we can see where the disagreements lie, within the data.

This would inform public policy, even if the initial analysis were from a sample of the population. We could use the data to prioritize laws, or study contradictions. And we could rate candidates based on how much they promised to move laws towards, or away from, your personal preferences.
Not science fiction, and already a dystopia
If you think this technology sounds far-fetched, like some kind of sci-fi utopia, consider this: It’s already here, and pervasive. Campaign strategists combine our demographic data with online quizzes, then use this to identify the places where we’re polarized, and to divide us.
If you think there’s a risk that such data could be used against us, consider this: It already is. It tricks us into voting for a single issue, and not listening to our political opponents. And it makes the law complicated and opaque in ways that line the pockets of lawyers at the expense of justice.
It seems a horrible misuse of technology to weaponize our moral compasses against us, rather than to use them to adjust our society and make better laws. Why benefit politicians instead of societies? Why not use these tools to find our common ground, in the open, and start from that? To identify where we differ, and have the hard conversations about what actually matters to us? Can we become moral ANIMALS?
Anyway, that’s what a summer learning to code taught me about politics.
Want to learn more about how we make moral decisions, and the neuroscience of what shapes our behaviour? Me too. I’ve been having a series of interesting conversations in public, and you’re welcome to join me for my next one, with behavioural economist Supriya Syal. It happens this Friday at noon Eastern.
Missed one of these chats? Here are the last two:
This week I interviewed author Misha Glouberman (about how he ran a birthday party) and founder/event organizer Sarah Shewey (about how she got married in a Cyberwedding.) We had a blast. If you want to watch the recording, check here.
I had a great conversation with Randy Smerik about how he pivoted a fine dining restaurant to virtual experiences in just a couple of weeks. The recording is here.